E0 E0 27 5C AB 60 C8 86 A3 FA C2 98 21 79 54 A8 9F D1 B9 DC 8A BA 84 EF B1 E7 C9 E2 1B F7 DD D7 DC F0 E4 4A BB 79 51 0E 7C EB 80 B1 1DHow did I find this? Strap in and let’s go for a ride. 🙂
The What
Quick recap: I want to unlock homebrew on the Pippin. Every time a Pippin tries to boot from an HFS volume on CD-ROM, it loads the ‘rvpr’ resource with ID 0 from ROM and executes it as code, passing as arguments that volume’s ID and two blocks of data found elsewhere in ROM. ‘rvpr’ 0 locates and reads an RSA-signed “PippinAuthenticationFile” from the volume. It contains a 128-bit digest for each 128K block in the volume, along with a 45-byte signature at the end of the file. If the signature cannot be verified or any of the digests don’t match what ‘rvpr’ 0 calculates from the volume in its main loop, the Pippin (r)ejects the disc.

Last time I looked at ‘rvpr’ 0, I examined and broke down what the main loop does at a high level. Outside of main, there are ten non-library function symbols in the resource, six of which I’ve identified their usage. Reading through these, I determined the format of the PippinAuthenticationFile and how its data is fed to the rest of the main loop. The remaining four functions—VerifyDigestInfo, VerifySignature, CreateDigest, and InitRSAAlgorithmChooser—form what I conjectured to be the “meat” of the authentication process. I elected to pore over these at a later time.
‘rvpr’ 0 is over 35K in size, with almost 34K of that comprised of 68K assembly code. Unfortunately, what I looked at in part 6 only touches about 3K of that—not even 10% of the whole. What’s worse is that the remaining 31K/90+% of code is almost completely lacking symbols, save for an occasional call to T_malloc, T_memset, T_memcpy, or T_free. Without human-readable symbols to guide what the remaining memory locations, values, and functions mean in the context of ‘rvpr’ 0’s greater purpose, I would be “flying blind” without a safety net. If I was to attempt to grok this code to the same degree as I currently understand main and its (named, mind you) auxiliary functions, I would have a long road ahead of me especially if I used the same static analysis technique of stepping through the code offline on paper.
The Why
I decided that the best way to figure out the rest of this code was to use dynamic analysis; that is, to examine it while it’s running. There were just too many subroutines and too much data being pushed around to keep it all straight in my head. I needed a computer to help. I don’t have any hardware debuggers for the Pippin that would allow me to step the CPU and examine the contents of RAM, and no working software emulators exist for the Pippin (yet). What I found does exist is a suite of 68K assembly tools—a code editor, binary editor, and, crucially: a simulator—called EASy68K. If I wanted to look at ‘rvpr’ 0 in something that even somehow resembled a debugger, I’d have to build a working version of ‘rvpr’ 0 that could be run outside of a Pippin, without first understanding how the code works in the first place.
EASy68K’s simulator provides a hypothetical computer system featuring a 68K CPU, 16MB of RAM, and rudimentary I/O facilities. Luckily, ‘rvpr’ 0 is pretty self-contained, which allowed me to quickly “port” it to EASy68K. I was correct in that this technique significantly accelerated my understanding of the digesting and verification process, but as I hope to elucidate later in this post, that pursuit required very little actual parsing of code. 🙂
The How
The first step to building an ‘rvpr’ 0 replica in EASy68K was to adopt the syntax EASy68K likes. I prefer FDisasm for disassembly because it’s part of the Mini vMac project and as such, it’s at least a tiny bit aware of the classic Mac OS API, known as the Toolbox. FDisasm can replace raw A-traps (two-byte 68K instructions beginning with the hex digit $A, which typically map to commonly-used subroutines) with their corresponding human-readable names according to official Mac documentation, which is a nice time-saver especially in large blocks of 68K Mac code. I also like FDisasm’s output formatting, which is the basis of how I list 68K assembly in these blog posts.
Cloning ‘rvpr’ 0 in EASy68K serves two purposes. First, I can step through it using a real signed Pippin CD, observe what its code does, and document it. After I reverse-engineer the authentication process though, this functional copy will serve a second purpose: to verify that my own authentication files are crafted properly. Since we know from part 2 and part 6 that the main loop will return zero in register D0 if the verification process succeeds, we should be able to observe that in the simulator. Using our own ‘rvpr’ 0 binary that’s as close as possible to what’s in ROM on an actual Pippin should assuage doubt as to whether a proof-of-concept will pass the console’s tests or not. Plus, since it’s all simulated in software, it saves me from having to burn a ton of test CDs. 😛
Converting my (annotated) disassembly from FDisasm’s syntax to EASy68K’s was easy—regular expressions to the rescue. Assembling the result produces code identical to what’s in the original resource—yay, the assembler works, and we have a byte-for-byte clone of what’s in the Pippin ROM. But making this new replica functional required a little bit of creativity.
On a real Pippin, ‘rvpr’ 0 is loaded from the ROM’s resource map into an area on the system heap in RAM. The relocation code at the beginning of ‘rvpr’ 0 patches each subroutine jump by offsetting them relative to where the code resides in RAM (discussed in part 6). It keeps track of whether this is done by storing this offset in a global when relocation is complete. Recall from part 3 that this global has an initial value of zero when ‘rvpr’ 0 is first run. If this code is executed a second time, it subtracts this global from its base address in RAM and, if the result is zero, it doesn’t need to do relocation again since the jumps already have valid destination addresses.
The simulator comes with no bootloader at all but starts up fully initialized, so in essence the contents of ‘rvpr’ 0 form the “ROM” of our virtual computer. We thus boot directly to ‘rvpr’ 0’s entry point, at the start of the simulator’s memory space. But since ‘rvpr’ 0 now always starts at address 0, the difference between that initial global and our base address… is zero. So the relocation code never runs in the simulator; it doesn’t have to because those unpatched jumps are already relative to zero. 😉
By the time ‘rvpr’ 0 executes in a real Pippin’s boot process, many subsystems on the console have been readied: the QuickDraw API for graphics, the Device Manager for device I/O, and the HFS filesystem package to name a few. These APIs, having been designed and built by Apple for the Mac, only exist on a Mac-based system and therefore naturally aren’t present in the fantasy system we get from EASy68K. We are in luck though in that ‘rvpr’ 0 only makes calls to a grand total of nine Toolbox APIs. Four of these calls are used in the “prologue” code discussed earlier that relocate all the jumps before main is even called. Since that relocation code doesn’t run in our simulator, that leaves five Toolbox APIs essential to the main loop: _Read, _Random, _NewPtr, _DisposePtr, and _BlockMoveData. We need equivalents to these routines if we are to expect ‘rvpr’ 0 to work properly.

_BlockMoveData is an easy one. It copies D0 bytes from (A0) to (A1):
_myBlockMoveData
8DCA 12D8 Move.B (A0)+, (A1)+
8DCC 5380 SubQ.L #1, D0
8DCE 6CFA BGE.B _myBlockMoveDataI took a shortcut with _Random: my implementation simply returns a constant value. I did this partially because I’m lazy but also because _Random is only called once, albeit in a loop: to determine which 128K chunks to digest. By controlling the values returned, I can selectively and deterministically test chunk hashing.

I took similar liberties with _NewPtr and _DisposePtr: I keep a global pointing to the next unused block, and _NewPtr simply returns the value of that global and then advances it by the requested size. _DisposePtr is implemented as a no-op. Why did I do this? Well, again, part of it is because I’m lazy and didn’t want to write a proper heap allocator for this, but also because it affords me the ability to inspect memory blocks used even after they’ve been “freed.” I don’t care about memory leaks in this case—in fact, here they’re a feature! 🙂 Since ‘rvpr’ 0 is roughly 36K, I set aside the first 64K of memory for it (and any additional supporting code/data I add, like these replacement Toolbox routines). With register A7 initially pointing to the top of memory for use by the stack, the rest of RAM starting at $10000 I designate for my “heap.”
Finally we come to _Read. EASy68K may be pretty bare-bones, but it does come with some niceties allowing for basic interactions with its host PC. In this case, I needed a way for my “virtual Pippin” to have random-access readability from a virtual CD-ROM drive. Fortunately, EASy68K provides this in the form of the Trap #15 instruction. My version of _Read only does the bare minimum of what ‘rvpr’ 0’s main loop requires: it opens an HFS disk image on the host PC, seeks to the offset specified in the ParamBlockRec passed on the stack, reads the requested amount of bytes into the specified buffer, then closes the file.
_myFilename
8DF0= 6361 6E64 ... DC.B 'candidate.hfs', 0
_myRead
8DFE 43F9 0000 8DF0 Lea.L _myFilename, A1
8E04 303C 0033 Move #51, D0
8E08 4E4F Trap #15
8E0A 2428 002E Move.L $46(A0), D2
8E0E 303C 0037 Move #55, D0
8E12 4E4F Trap #15
8E14 2268 0020 Move.L $32(A0), A1
8E18 2428 0024 Move.L $36(A0), D2
8E1C 303C 0035 Move #53, D0
8E20 4E4F Trap #15
8E22 303C 0032 Move #50, D0
8E26 4E4F Trap #15
8E28 303C 0000 Move #0, D0Now that we’ve got functional replacements for the necessary Toolbox routines, how do we refit the rest of the code so that our versions are called instead of Apple’s, which don’t exist? I already had the Toolbox API names substituted in my listing, thanks to FDisasm, so I could simply create macros with those names that execute a tiny bit of code in place of those calls. The easiest way, and the method I tried first, is to invoke each replacement with a Jsr instruction, which is short for “Jump to SubRoutine.” This was really straightforward to do and assembled without issue, but upon loading and running in the simulator, I quickly discovered why this approach wouldn’t work. Jsr is a four, sometimes six byte instruction, whereas the original A-traps they were to replace use only two bytes. Since these larger instructions are inserted in the main loop near the beginning of the code, this throws off hardcoded addresses used later. Needless to say, when I ran in the simulator, a hardcoded Jsr landed instead in an unexpected area of code and I crashed almost instantly.
However I was going to invoke my faux-Toolbox calls, they had to be done in only two bytes. I thought for a second about how I could write an A-trap exception handler and leave Apple’s original A-trap instructions as-is, but I didn’t do that either because 1) laziness and 2) I thought of an easier way. Remember the Trap #15 instruction I used to implement _Read?
On a 68K processor, the two-byte Trap instruction provides a way to jump to any of 16 different addresses stored in a predefined area of memory, known as “vectors.” These 32-bit vectors are all stored consecutively in a block of memory that always starts at address $80. ‘rvpr’ 0 normally executes code at address $80, but that’s part of the address relocation done only on a real Pippin, not in our simulator. It is therefore safe for us to replace that block of code with the addresses of our replacement Toolbox routines, starting with Trap #0 and ending with Trap #3. Recall that I’ve implemented _DisposePtr as a no-op—which is the two-byte opcode $4E71—so I don’t need to set aside a trap vector for it. EASy68K only sets aside trap 15 for itself, leaving traps 0-14 for us to use however we wish. The code we do care about executing in the simulator doesn’t start until after address $100, so our entire trap table easily fits inside this block of unused code. How lucky can you get? 🙂
My very own Pippin “emulator”
With my cobbled-together Pippin “emulator” now up and running, finally I could take a look at the before and after of the remaining functions called by the main loop. I decided to start with CreateDigest, as I had already figured out the inner workings of CompareDigests, so this seemed like a simple starting point. CreateDigest starts by creating a context object for itself, and initializes one of its buffers with a curious but predictable pattern of 16 bytes: 67 45 23 01 EF CD AB 89 98 BA DC FE 10 32 54 76. Along the way it checks to see if any of this setup fails, and if so, the entire authentication check is written off as a failure. But assuming everything is fine, it enters a loop which digests our 128K input chunk up to 16K at a time, by passing each 16K “window” to an unnamed subroutine. Each time we iterate through this loop, the aforementioned buffer which was initially filled with a predictable pattern now instead contains a brand new seemingly random jumble of numbers. I suspected that this 16-byte buffer was used as a sort of working space for whatever Apple chose as a hashing algorithm, since its size matched that of the digests in the PippinAuthenticationFile.
createDigestLoop
764 B883 Cmp.L D3, D4 ; chunk size > 16K?
766 6C02 BGE.B dontResetD3 ; if so, use 16K for window size
768 2604 Move.L D4, D3 ; otherwise we have <16K left, so use what's left as window size instead
dontResetD3
76A 4878 0000 Pea.L ($0) ; push zero
76E 2F03 Move.L D3, -(A7) ; push window size (typically 16K until the end)
770 2F0A Move.L A2, -(A7) ; push working chunk buffer ptr
772 2F2E FFFC Move.L -$4(A6), -(A7) ; push ptr to our hash buffer
776 4EB9 0000 6516 Jsr Anon217 ; patched, creates hash? digest?
77C 2A00 Move.L D0, D5
77E 4A85 Tst.L D5
780 4FEF 0010 Lea.L $10(A7), A7 ; cleanup stack
784 6628 BNE.B createDigestCleanup ; if Anon217 failed, bail
786 9883 Sub.L D3, D4 ; subtract window size from chunk size
788 D5C3 AddA.L D3, A2 ; advance working chunk buffer to next 16K-ish window
endOfCreateDigestLoop
78A 4A84 Tst.L D4 ; still more data to hash/digest?
78C 6ED6 BGT.B createDigestLoop ; hash/digest it
78E 4878 0000 Pea.L ($0) ; push zero
792 4878 0010 Pea.L ($10) ; push 16
796 486E FFF8 Pea.L -$8(A6) ; push address of local longword
79A 2F2E 0010 Move.L $10(A6), -(A7) ; push out buffer ptr
79E 2F2E FFFC Move.L -$4(A6), -(A7) ; push ptr to our hash buffer
7A2 4EB9 0000 654C Jsr Anon218 ; patched, copies hash out?
7A8 2A00 Move.L D0, D5
7AA 4FEF 0014 Lea.L $14(A7), A7 ; cleanup stackFinally, CreateDigest makes one more call to an unnamed subroutine, passing it among other things the number 16 (presumably the digest size in bytes), a pointer to its context object, and a pointer to a 16-byte area on the stack filled with $FF bytes. After this call, the working buffer is once again reset to its initial pattern, and the area on the stack is filled with what looks like it could be a digest.
Wait a minute, upon closer examination...
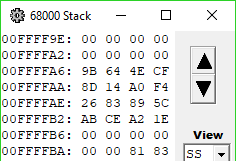
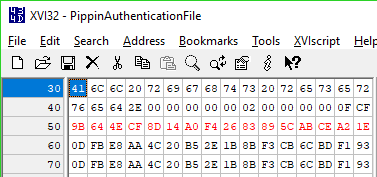
... the output hash matches what's in the PippinAuthenticationFile! This makes sense, because all CreateDigest does after this is tear down and dispose of its context object. It then returns to the main loop, where the computed digest is passed along for CompareDigests to, well, compare. So clearly those two unnamed subroutines play a vital role in computing the digest, however that's done.
I dove right in to the routine called in the loop. It starts by doing several integrity checks of the data structures it's about to use, then goes right into a confusing routine that appears to add the amount of bits in our up-to-16K input window to a counter of some sort, optionally increasing the next byte if the counter rolls over. I suspected this was used for a 40-bit counter of bits hashed, its purpose not obvious yet. It then enters a loop of its own, dividing our input window into yet another sliding window, this time of 64 bytes in size. Each iteration of this loop, it passes these 64 bytes and CreateDigest's 16-byte working buffer to an unnamed subroutine with some very interesting behavior.
7186 2612 Move.L (A2), D3
7188 282A 0004 Move.L $4(A2), D4
718C 2A2A 0008 Move.L $8(A2), D5
7190 2C2A 000C Move.L $C(A2), D6
7194 4878 0040 Pea.L ($40)
7198 2F2E 000C Move.L $C(A6), -(A7)
719C 486E FFC0 Pea.L -$40(A6)
71A0 4EB9 0000 7C58 Jsr ($7C58).L
71A6 2004 Move.L D4, D0
71A8 4680 Not.L D0
71AA C086 And.L D6, D0
71AC 2204 Move.L D4, D1
71AE C285 And.L D5, D1
71B0 8280 Or.L D0, D1
71B2 D2AE FFC0 Add.L -$40(A6), D1
71B6 0681 D76A A478 AddI.L #$D76AA478, D1
71BC D681 Add.L D1, D3
71BE 2003 Move.L D3, D0
71C0 7219 MoveQ.L #$19, D1
71C2 E2A8 LsR.L D1, D0
71C4 2203 Move.L D3, D1
71C6 EF89 LsL.L #$7, D1
71C8 8280 Or.L D0, D1
71CA 2601 Move.L D1, D3
71CC D684 Add.L D4, D3Looking at this new subroutine, I was fairly convinced that it does the actual hashing. It is an unrolled loop that does a number of bitwise operations before adding a longword (32-bit quantity) from our input window along with what appear to be magic numbers to one of four 32-bit registers. At the end of this function, the contents of these registers are concatenated and added to the existing contents of CreateDigest's 16-byte working buffer. In order to maybe recognize a pattern to what this hash function was doing and perhaps identify the algorithm, I converted this assembly back to C code, and then verified that my C version produced identical output. Unfortunately, the algorithm didn't look familiar to me at all—I assumed it was something Apple invented specifically for the Pippin. I feared the initial "salt" might not be constant and could change depending on where the input chunk exists in the volume. Perhaps I merely found one hash function, but the Pippin could switch between different hash functions depending on some heuristic? It would require more disassembly and careful analysis to verify whether or not this was the case and why. 🙁
A Fun Side Story
Last Friday was 4/26, known informally among fans as Alien Day. I’m a big fan of the Alien universe, and this year happens to be the 40th anniversary of the 1979 Ridley Scott classic. So on Friday I had a number of friends over to watch both Alien films. 😉 There was pizza, chips, my homemade queso (half a box of Velveeta + a can of Rotel chiles—nuke it in the microwave for five minutes, stirring occasionally), and everybody had a good time.
One of the folks who dropped by was my friend Allison, who wanted to leave me with a disc of early Xbox demos her wife Erica found for me. I’m interested in investigating the contents of this disc in case there’s anything of historical value on it, but Xbox discs cannot be mounted or copied using a run-of-the-mill DVD-ROM drive. I remember years ago burning one or two (homebrew, ahem) Xbox DVDs with my PC, so I know writing Xbox discs is possible, but I was curious why reading them posed such an obstacle.

After some Googling, I found that the Xbox employs its own scheme to verify and “unlock” a boot disc candidate (described by none other than Multimedia Mike—an intrepid hacker whose blog I recommend). As I read, I learned that the Xbox’s disc verification involves the host (in most cases, an Xbox) answering an encrypted series of challenges at the drive level. This process, which is unique to each Xbox disc, uses SHA-1 hashes and RC4 encryption. This is a pretty cool and fascinating way to hide Xbox game data from non-Xboxes—it’s definitely worth checking out the details.
As one does on a Friday evening, I found myself clicking through to the Wikipedia entry on SHA-1. Not much time later, I was deep in the Wikipedia rabbit hole, ultimately landing on the page describing the MD5 message digest algorithm. Those of you reading this who have at least a passing familiarity with cryptography might recognize where this is going based on my description of CreateDigest's behavior above. I did not. 😛
MD5
I just accidentally learned the MD5 algorithm. 😉
— Keith Kaisershot (@ablitter) April 27, 2019
According to Wikipedia, MD5 was designed in 1991 by Ronald Rivest, one of the inventors of the RSA cryptosigning algorithm used by the Pippin. MD5 was designed to replace an earlier version, MD4, which traded better security for increased performance. At a basic level, MD5 takes a bitstring of arbitrary length—the "message"—and generates a 128-bit string that uniquely identifies this input, called a "digest." The input string is padded to a multiple of 512 bits by adding a 1 bit, a number of zero bits, and finally the size of the original message in bits, stored as a little-endian 64-bit value. The padded message is finally split into chunks of 16 longwords, and these 64-byte chunks are then passed into MD5's core hash function to be added to a final 16-byte digest. If that sounds confusing, here's a summary: MD5 takes an arbitrary-sized message and turns it into a unique fixed-size message. The same input will result in the same output, but no two distinct inputs will result in the same output (this isn't 100% true, but for the purpose of this discussion we'll pretend it is).
On the surface, MD5 sounded like it might be what Apple adopted as the Pippin's digest algorithm, but I knew I'd hit paydirt when I instantly recognized the "magic numbers" used in its reference implementation. What's more, the Transform function looked almost exactly the same as the C code I derived from that unnamed subroutine in 'rvpr' 0, and the MD5Update function likewise performs the same steps as the 68K routine that calls into Transform. I am confident that Apple licensed this particular implementation for use in the Pippin. It follows the MD5 specification to the letter, even going so far as endian-swapping the input longwords from the Pippin's native big-endianness.
Armed with the knowledge that MD5 is the message digest algorithm used in the Pippin authentication process, it is clear that the digests computed in CreateDigest, and the digests read from the PippinAuthenticationFile used in CompareDigests, are themselves not signed with RSA. In fact, RSA is not involved with verifying chunks of the disc at all. This tells me that the only thing RSA is used for in the authentication process is for verifying the signature at the end of the PippinAuthenticationFile.

The signature, to recap, is 45 bytes long and lives at the end of the PippinAuthenticationFile. Before entering the main loop, 'rvpr' 0 makes a call to VerifyDigestInfo, which in turn makes a call to VerifySignature. VerifySignature calls upon MD5 to digest the "message" portion of the PippinAuthenticationFile—everything but the signature. It then must use RSA to decrypt and verify the signature against that MD5 digest. If it does, we know the chunk hashes therein can be trusted, so RSA is no longer needed. Otherwise, we know the PippinAuthenticationFile has been tampered with in some way.
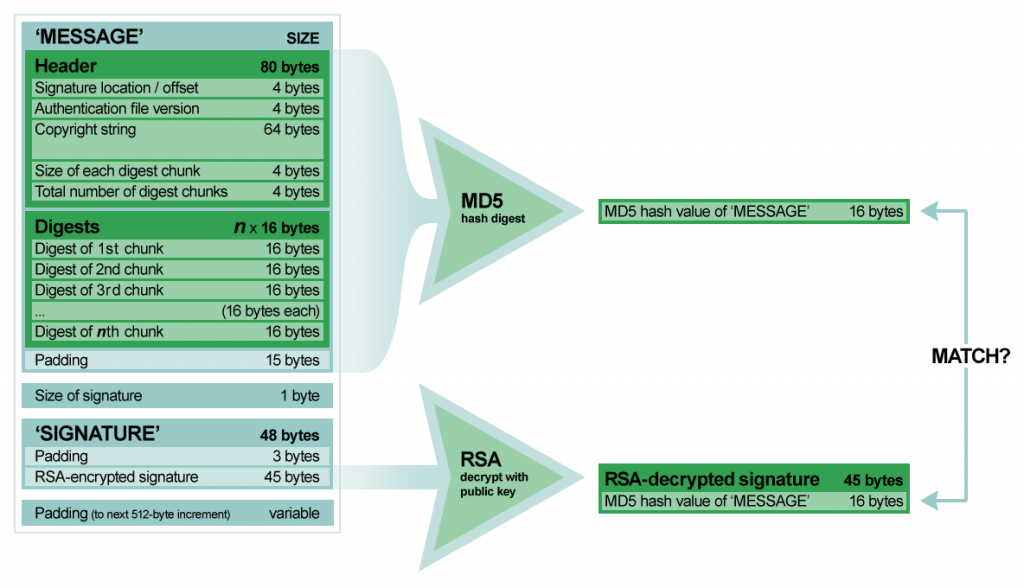
Let's say for illustration's sake that the PippinAuthenticationFile is 64K and the last 1K is the signature. When the signature is decrypted, it should contain a digest of that first 63K. If we digest that first 63K ourselves and the two match, we're verified. The whole process is... pretty modern, actually, when you consider this was 1995. 🙂
Using the "Macintosh on Pippin" CD (a.k.a. "Tuscon") as a test case, I stepped through VerifySignature to obtain the MD5 digest of the authentication file's "message:" AE 1A EC AE A4 C5 11 68 2E 38 7D D1 48 F0 55 C2. With this in mind, I set out to test my hypothesis and hopefully find our computed MD5 digest of the message portion somewhere in memory. If I could find this, I could work backwards and reveal how the signature is decrypted. Apple indicated in a Pippin technote that RSA was licensed for their authentication software library. Whether this means Apple used the library as-is, or licensed the code to augment for their own needs, I wanted to verify this one way or the other. VerifySignature makes two unnamed calls before cleaning up and returning a result:
668 B883 Cmp.L D3, D4 ; is the remaining bytes to hash greater than 16K
66A 6C02 BGE.B (* + $4) ; then hash another 16K
66C 2604 Move.L D4, D3 ; else hash the remaining bytes (which will be < 16K)
66E 4878 0000 Pea.L ($0)
672 2F03 Move.L D3, -(A7) ; push size as bytes to hash (typically 16K until the last chunk)
674 2F0A Move.L A2, -(A7) ; push ptr to start of chunk to hash
676 2F2E FFFC Move.L -$4(A6), -(A7) ; -$4(A6) -> hash object
67A 4EB9 0000 816C Jsr ($816C).L ; create digest of 16K chunk in hash object
680 2A00 Move.L D0, D5 ; (don't know what is returned in D0, I think a size?)
682 9883 Sub.L D3, D4 ; remaining bytes -= how many bytes we just hashed (typically 16K)
684 D5C3 AddA.L D3, A2 ; A2 -> next chunk to hash
686 4FEF 0010 Lea.L $10(A7), A7 ; cleanup stack
68A 4A84 Tst.L D4 ; are there any remaining bytes left?
68C 6EDA BGT.B (* + -$24) ; keep hashing
68E 4878 0000 Pea.L ($0)
692 4878 0000 Pea.L ($0)
696 2F2E 001C Move.L $1C(A6), -(A7) ; $1C(A6) == $2D (size of signature?)
69A 2F2E 0018 Move.L $18(A6), -(A7) ; $18(A6) -> second longword in data block after hashes in auth file (start of signature?)
69E 2F2E FFFC Move.L -$4(A6), -(A7) ; -$4(A6) -> hash object
6A2 4EB9 0000 81A2 Jsr ($81A2).L ; probably decrypt the signature?
6A8 2A00 Move.L D0, D5
6AA 4FEF 0014 Lea.L $14(A7), A7 ; cleanup stackI knew that the first call at $816C computes the MD5 digest of the PippinAuthenticationFile. I intuited that in order to determine whether verification succeeds, whatever occurs in the second call at $81A2 must accomplish that. Therefore, the public key must exist in memory at some point during $81A2's execution. In addition, the signature bytes must exist in memory at the same time. If I drill down into $81A2 until I find the signature bytes in RAM, I should find clues as to what data is used to decrypt it based on the proximity of what's changed to what hasn't, thanks to how I implemented my "heap."
$81A2 eventually makes its way to a subroutine at $1B0E, wherein I found the following:
1B58 2F0B Move.L A3, -(A7) ; push nullptr?
1B5A 4878 0000 Pea.L ($0) ; push 0
1B5E 2F04 Move.L D4, -(A7) ; push size of signature?
1B60 2F05 Move.L D5, -(A7) ; push address of signature?
1B62 42A7 Clr.L -(A7) ; push 0
1B64 486E FF78 Pea.L -$88(A6) ; push ptr to area on stack
1B68 4878 0000 Pea.L ($0) ; push 0
1B6C 486A 0028 Pea.L $28(A2) ; push ptr to $10F0 in hash object?
1B70 4EB9 0000 12E0 Jsr ($12E0).L ; jump somewhere that copies the signature to a working buffer
1B76 2600 Move.L D0, D3 ; D0 == result code
1B78 4FEF 0020 Lea.L $20(A7), A7
1B7C 6600 00AE BNE (* + $B0) ; if it's nonzero, bail
1B80 2F0B Move.L A3, -(A7) ; push nullptr?
1B82 4878 0000 Pea.L ($0) ; push 0
1B86 4878 0040 Pea.L ($40) ; push 64
1B8A 486E FF98 Pea.L -$68(A6) ; push ptr to somewhere on stack
1B8E 486E FFA8 Pea.L -$58(A6) ; push ptr to somewhere else on stack
1B92 486A 0028 Pea.L $28(A2) ; push ptr to $10F0 in hash object?
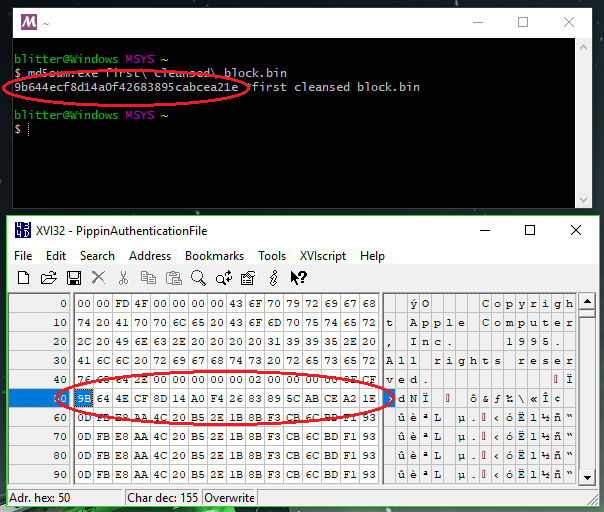
1B96 4EB9 0000 13D8 Jsr ($13D8).L ; jump somewhere, get processed data we care about on stack$12E0 copies our signature from the PippinAuthenticationFile into a working buffer shortly after a copy of part of the data block in ROM passed to 'rvpr' 0 upon initial invocation. Could the "processed data" coming from the subroutine at $13D8 be our decrypted signature? I took a look at the memory before and after the call, and...
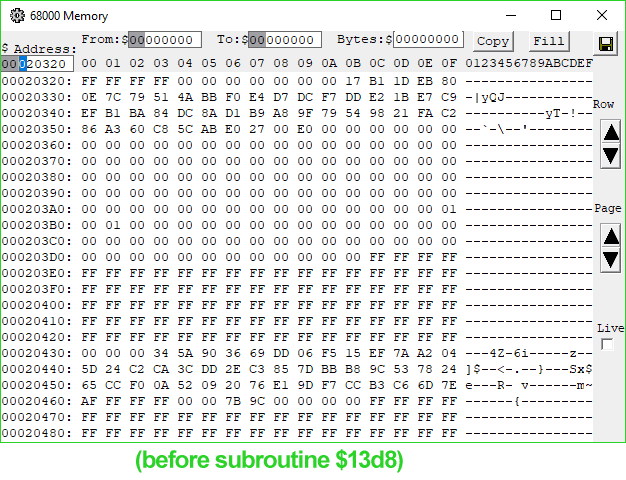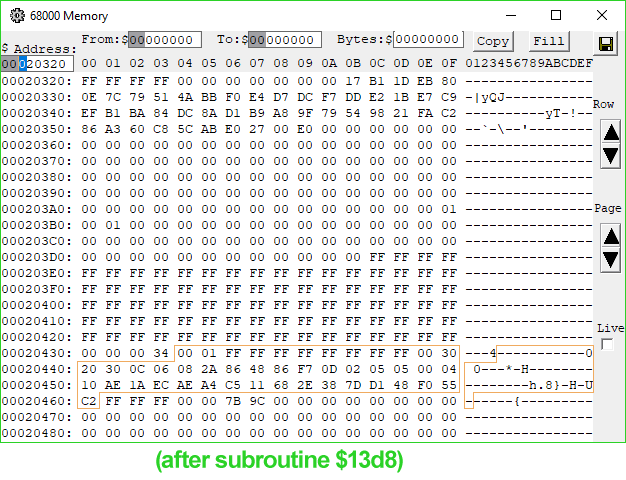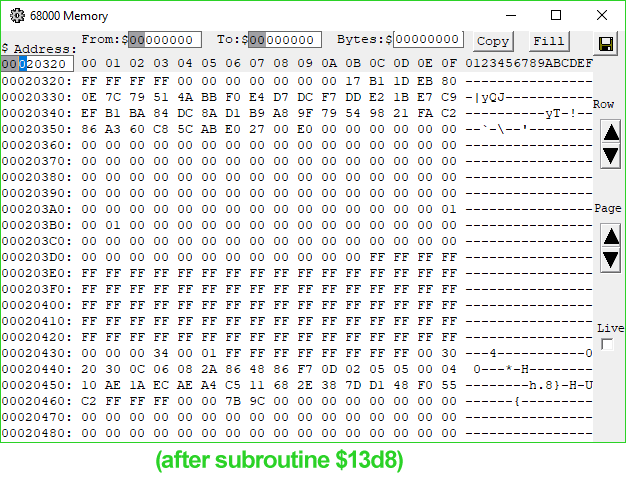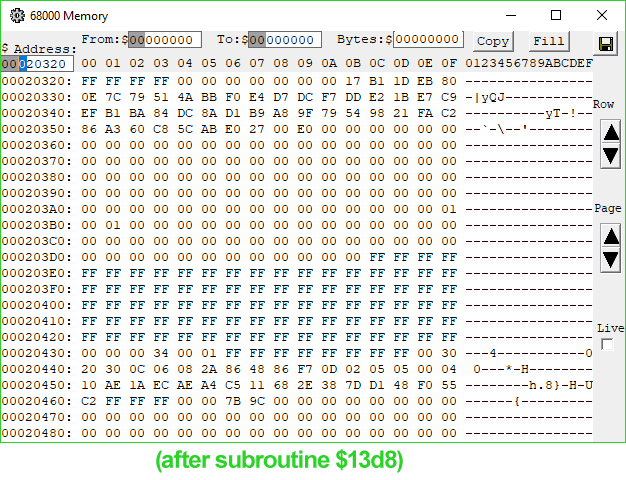
Look at memory location $20451.
When I saw it, I gasped. There it is. There's our decrypted digest.
I wasn't as lucky with the RSA code as I was with MD5—neither the reference implementations 1.0 nor 2.0 of RSA have portions that appear in this code, but they do answer the question of the signature format. The bytes appearing before our decrypted digest are a header consisting mostly of magic numbers and some $FF padding bytes, but with a lonely "05" byte at address $2044C, or offset 24 into our decrypted signature. This byte's value indicates that the digest is an MD5 digest, just like the reference implementation specifies.

That completed my understanding of the format of the PippinAuthenticationFile, leaving only one final piece of the puzzle: what and where the public key is. The public key must come from somewhere, but at this point I hadn't yet determined the purpose of the data passed in from ROM to 'rvpr' 0...
RSA (in which I dust off my math minor)
The RSA algorithm for cryptosecurity, invented in 1977 by Ronald Rivest, Adi Shamir, and Leonard Adleman, is built upon the notion that factoring large semiprime numbers is considered a hard problem. Not impossible, but very hard. Finding these primes can take a computer or cluster of computers a significant amount of time, proportional to the size of the semiprime to factor. Mathematically, it involves a few steps but can be implemented using basic algebraic concepts.
First, find two numbers 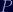

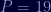

Next, compute 

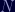
Now we need to calculate 

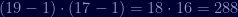
We need to choose a value for 
Finally we need to find the value of 

All we do here is integer divide 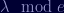

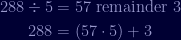
Take the divisor from that and divide by the remainder:
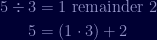
One more time:
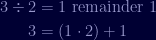
Once we have a remainder of one, we've found the greatest common divisor and so we need to build back up to find our value for
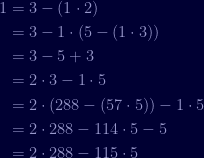
Since we need to satisfy 
We now have everything we need to sign and verify messages. Our "private key" is our values for
Let's say we want to send someone the answer to the ultimate question, but we want to sign it first in case our message gets intercepted by Vogons. 😛 Call the original message 
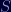

When our recipient receives our message, they will need to verify our signature in order to be sure it can be trusted and that it has not been tampered with by any poetic aliens. 😉 They do so using our values for
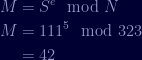
If the signature matches the original message (as it does here in our example), the message arrived safely intact.
Notice that the values for
The signature size as defined in the PippinAuthenticationFile is 45 bytes, suggesting that the Pippin's public RSA key is at least 360 bits long (45 * 8 bits per byte). Recall from earlier that although the RSA public key is still unknown, it must come from somewhere in the ROM, and it is still at this point unclear what purpose the blocks of data passed to 'rvpr' 0 serve.
I found part of one of the blocks in RAM near where the decrypted signature is: 45 bytes, same as the signature. I also found a nearby value of 0x10001, or 65537, which seems to be a popular choice for the value of
I found another block of memory also nearby containing the same data, but reversed by 16-bit words. Hmm. Interesting.
Wonder what the odds are... 😉
It was reasonable to hypothesize that one of these blocks contained the public key. There are plenty of web pages out there that explain RSA using examples, some with implementations in JavaScript allowing someone to plug in their own keys, messages, and signatures. I tried the nearest 45-byte "key" in one such website with the raw 45-byte signature from the PippinAuthenticationFile and...
It didn't work. The "decrypted" signature didn't match at all. Garbage in, garbage out. Cue sigh of disappointment.

I had one data block left, and with little hope remaining...
*gasp!*
I'd found it.
Apple's public key for verifying the signature on a PippinAuthenticationFile is:
E0 E0 27 5C AB 60 C8 86 A3 FA C2 98 21 79 54 A8 9F D1 B9 DC 8A BA 84 EF B1 E7 C9 E2 1B F7 DD D7 DC F0 E4 4A BB 79 51 0E 7C EB 80 B1 1D
... and I didn't even have to look at very much code. 😀
Cracking RSA
I just have to crack RSA now, right?
Fortunately, available tools make that a much less daunting prospect than popular media contemporary with the Pippin suggested. There was even an ongoing RSA Factoring Challenge for a while until 2007. Back then though, it was a different story. The Open Source Initiative had yet to be founded. Prime factoring was done mostly in isolation by dedicated teams with access to massive amounts of computing power (for the time). A 364-bit decimal number took a two-person team and a supercomputer about a month to factor in 1992.
But this isn't 1992 anymore. The computers on our desks and in our pockets have more than enough number-crunching power to factor the Pippin's public key. Today, with some freely available open source software and a typical desktop PC, a 360-bit key can be factored in a matter of hours. And thanks to the efforts of several open source projects within recent years, we have a little tool to help us called msieve. 😀
msieve is very user-friendly. 😉 You pass the number you want to factor as its only command line argument and it just goes. It even saves its progress to disk, just in case it's a Really Big Number and something terrible happens like a power outage or something.
msieve took 18 hours, 34 minutes, and 4 seconds on my i7 Intel NUC to find two prime factors
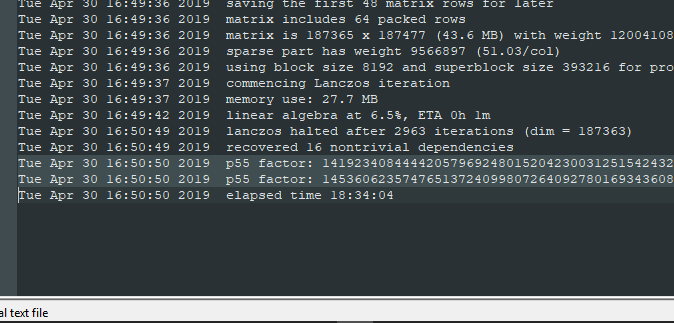
Let's plug these into our RSA formulas from above and find Apple's private key, shall we?
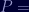
0F 2D 25 BF 3C 5B 70 28 72 6E 49 75 3F D5 62 67 11 37 38 94 51 EF D7
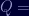
0E D1 47 5D E1 92 41 28 59 2C 4B 3E 47 4E 5F C1 23 1F 1B AF A0 D8 2B
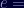
0x10001
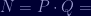
E0 E0 27 5C AB 60 C8 86 A3 FA C2 98 21 79 54 A8 9F D1 B9 DC 8A BA 84 EF B1 E7 C9 E2 1B F7 DD D7 DC F0 E4 4A BB 79 51 0E 7C EB 80 B1 1D (this is the public key—we know this from stepping through 'rvpr' 0 and examining memory)
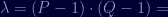
E0 E0 27 5C AB 60 C8 86 A3 FA C2 98 21 79 54 A8 9F D1 B9 DC 8A BA 66 F1 44 CA AB F4 6A A7 12 3D 48 3D 5D 26 F9 51 1C B8 28 A7 8D E9 1C

01 1C D3 AD E7 99 86 67 D6 E9 E2 17 11 DB EC 33 07 B6 0E 4D 6D 03 26 20 77 5D DB 9B 3B 64 CF 22 B2 0E 4A F3 2F 07 40 EE B0 6F 85 F2 A0 1D
That last value for
Its first four bytes indicate a message size of $FD4F, or 64847 bytes. The MD5 digest of those first 64847 bytes is AE 1A EC AE A4 C5 11 68 2E 38 7D D1 48 F0 55 C2.
It has the following signature:
5A 90 36 69 DD 06 F5 15 EF 7A A2 04 5D 24 C2 CA 3C DD 2E C3 85 7D BB B8 9C 53 78 24 65 CC F0 0A 52 09 20 76 E1 9D F7 CC B3 C6 6D 7E AF
When decrypted, we get:
00 01 FF FF FF FF FF FF FF FF 00 30 20 30 0C 06 08 2A 86 48 86 F7 0D 02 05 05 00 04 10 AE 1A EC AE A4 C5 11 68 2E 38 7D D1 48 F0 55 C2
Notice that the last 16 bytes match our computed MD5 digest.
Finally, if we take the decrypted signature and re-sign it using what we think is Apple's private key, we get:
5A 90 36 69 DD 06 F5 15 EF 7A A2 04 5D 24 C2 CA 3C DD 2E C3 85 7D BB B8 9C 53 78 24 65 CC F0 0A 52 09 20 76 E1 9D F7 CC B3 C6 6D 7E AF
... which matches the original signature found in the PippinAuthenticationFile.

Apple’s public key for verifying the PippinAuthenticationFile is:
E0 E0 27 5C AB 60 C8 86 A3 FA C2 98 21 79 54 A8 9F D1 B9 DC 8A BA 84 EF B1 E7 C9 E2 1B F7 DD D7 DC F0 E4 4A BB 79 51 0E 7C EB 80 B1 1D
Apple’s private key for signing a PippinAuthenticationFile is:
01 1C D3 AD E7 99 86 67 D6 E9 E2 17 11 DB EC 33 07 B6 0E 4D 6D 03 26 20 77 5D DB 9B 3B 64 CF 22 B2 0E 4A F3 2F 07 40 EE B0 6F 85 F2 A0 1D
There you go, Internet. We now have all the information we need to sign and boot our own Pippin media.
awesome !
Wow. Your work is impressive.
The very last block of a HFS volume is apparently unused, which makes it a very good place to put a small authentication file, in my opinion. No need to worry about actually making a file to put the auth info in.
It seems pretty easy to make a tool that takes an .iso, finds all the volumes, and makes minimal auth info for each. It wouldn’t even increase the size of the disk image.
This is absolutely incredible! I doubt the Pippin homebrew game scene will be alive and kicking after this, but I’m still really impressed! 😀 It was an incredible ride.
congratulations on working on this. I was one of the 4 american software companies selected to build launch titles for the Bandai Pippin. I built the Flying Colors, DragonBall Z paint program, and Ultraman titles for the machine.
RSA was patented in the US until September 21, 2000. In 1995, Apple needed to license it to use it even if they wrote all the code themselves.
Funnily enough, I remember the gaming press being cautiously optimistic about the Pippin. It was touted as a multimedia console hybrid. Back then, something being Multimedia was a big marketing buzzword (think a bit like cloud or blockchain). The general feeling I recall is similar to when Windows CE came to the Dreamcast, or when the original Xbox launched.
Really great work on this, especially on the dissassembly. I followed the Hackaday article and started reading from the beginning of this project. I’m super familiar with how RSA works and factorization to crack private keys, so when I came across this post I made sure not to cheat by looking at your key recovery, but to reproduce that step myself. Msieve is great for composites up to about 315 bits or ~95 digits, using an algorithm called the self initializing quadratic sieve (SIQS) that definitely works for this case (360 bit or ~109 digit numbers), but is a good deal slower than the state-of-the-art (in 2019, even): the general number field sieve (GNFS). Using GGNFS software (a GNU’d implementation of GNFS) for the sieving, and YAFU software (Yet Another Factor Uility, which has msieve built into it) for the “post-processing” (filtering, linear algebra, and square-root steps that must be done for both GNFS and SIQS algorithms) I factorized n in 1 hour 35 minutes on a quad-core Intel i5-4570S from 2014. I repeated it on a more modern octo-core Intel i7-9700 and got the result in just 38 minutes. I started the SIQS on the i7-9700 and it looked like it would have taken at least 6 hours, so that shows just how effecient GNFS is over SIQS for composites of this size. I’ve done several 512-bit factorizations over the past few years and those take about 6 days with GNFS on the i7-9700.
With p and q in hand, I set out to reproduce the rest of your steps, but got a little thrown off. Your value for the decryption exponent D works, but it wasn’t what I got when I did it myself. There are two things different, interestingly: your D is larger than your chosen λ; and your choice for λ isn’t optimal.
Calculating D is finding a multiplicative inverse of e modulo λ, and when working mod λ you would typically find a D that satisfies 1 < D < λ. I say "_A_ multiplicative inverse" and "typically" because there are an infinite number of D's that work: the minimal D satisfies 1 < D = 0, that is, multiples of λ). Your workthrough used D’ (which has one extra copy of λ added to it, or D_1 from the generalized case), whereas the minimal D (D_0) is 3B F3 86 8A EE 25 9F 50 45 E7 54 79 BA 72 DE 5F 16 3C 93 90 78 6B B9 86 19 10 EF 46 FA 28 10 74 C6 0D 96 08 0D EF D1 F8 46 DE 64 B7 01. Your D’ is 361 bits, making it larger even than n; the minimal D with your chosen λ (itself 360 bits) is 358 bits.
We can optimize even further by using the minimal λ. You used the Euler totient function ϕ(n) = (p – 1) * (q – 1), which works as it is a multiple of the Carmichael totient function λ(n) = lcm(λ(p),λ(q)), and both λ(p) = ϕ(p) = p – 1 and λ(q) = ϕ(q) = q – 1 since p and q are prime. If you don’t remember your least common multiple, it’s related to the greatest common denominator by lcm(a, b) = a * b / gcd(a, b). In the instant case gcd(p – 1, q – 1) = 6 (it’s always guaranteed to be at least 2, since p and q are odd primes, then p – 1 and q – 1 are both even). So the optimal λ = 25 7A B1 3A 1C 90 21 6B C5 FF 20 6E B0 3E E3 71 6F F8 49 A4 C1 C9 BB D2 E0 CC 71 FE 11 C6 83 0A 36 B4 E4 DB D4 38 2F 74 06 C6 97 A6 DA. This can be obtained from your choice of λ by dividing out that factor of 6. I got all this info from, and it’s all better explained, typeset and annotated on the Wikipedia article for “RSA (cryptosystem)” so you can get a more through rundown from there.
Using the optimal 358-bit λ lets us calculate an optimal D that is also at most 358 bits. The final modular inverse gives D = 16 78 D5 50 D1 95 7D E4 7F E8 34 0B 0A 33 FA ED A6 44 49 EB B6 A1 FD B3 38 44 7D 48 E8 61 8D 6A 8F 58 B1 2C 39 B7 A2 84 40 17 CD 10 27 which is only 357 bits.
To wrap up, here are PEM encoded “Traditional OpenSSL” PKCS#1 (BEGIN RSA PRIVATE KEY) and PKCS#8 (BEGIN PRIVATE KEY) formats of this key (with the optimal λ and D parameters); PKCS#8 is pretty much just a wrapper around the PKCS#1, as PKCS#8 generalizes to being able to contain other asymmetric key types like DSA, ECDSA and even ED25519 and ED448.
—–BEGIN RSA PRIVATE KEY—–
MIHkAgEAAi4A4OAnXKtgyIaj+sKYIXlUqJ/RudyKuoTvsefJ4hv33dfc8ORKu3lR
DnzrgLEdAgMBAAECLRZ41VDRlX3kf+g0Cwoz+u2mREnrtqH9szhEfUjoYY1qj1ix
LDm3ooRAF80QJwIXDy0lvzxbcChybkl1P9ViZxE3OJRR79cCFw7RR13hkkEoWSxL
PkdOX8EjHxuvoNgrAhcKldPhOekRJrUB5aypNF1pRCG/DfzEiwIXBMlRll/xUJ7p
/0bm/T2x7L+douHewTUCFwIUDAoCaB1BP52Ire5+CtllVJ6EfhX2
—–END RSA PRIVATE KEY—–
—–BEGIN PRIVATE KEY—–
MIH8AgEAMA0GCSqGSIb3DQEBAQUABIHnMIHkAgEAAi4A4OAnXKtgyIaj+sKYIXlU
qJ/RudyKuoTvsefJ4hv33dfc8ORKu3lRDnzrgLEdAgMBAAECLRZ41VDRlX3kf+g0
Cwoz+u2mREnrtqH9szhEfUjoYY1qj1ixLDm3ooRAF80QJwIXDy0lvzxbcChybkl1
P9ViZxE3OJRR79cCFw7RR13hkkEoWSxLPkdOX8EjHxuvoNgrAhcKldPhOekRJrUB
5aypNF1pRCG/DfzEiwIXBMlRll/xUJ7p/0bm/T2x7L+douHewTUCFwIUDAoCaB1B
P52Ire5+CtllVJ6EfhX2
—–END PRIVATE KEY—–